上一個章節提到 normaliztion vectors 解決了我們用單字統計時會產生的問題
但是還有一個問題是,我們通常想強調文章中的某些關鍵詞
在開始討論關鍵詞之前,我們先來說說什麼事冷僻詞
假設有一篇關於足球的文章,當中一定會常常出現 Common words 而當中的 rare words 常常會被掩沒,原因是它們在詞料庫並不常見
所以我們該如何增加這些 rare words 的重要性呢?因為通常這些詞才是真正描述這篇文章獨到之處,因此我們必須設法增加它的權重
現在另一個問題是,我們只想強調 rare words 嗎?
毫無疑問我們想要屏除it、that、the 這些 Common words ,但是跟球類相關的 player、field、goal 甚至有些詞像是 soccer 可以明確將運動的類型區隔開來,同樣的在籃球也會出現 player、field、goal 但你會在文章當中找到 basketball 而不是 soccer 或是 hoop(籃框)/offside(越位)
在這個例子中,我們想強調的單字,稱為 important words
在 important words 當中也有我們想要的詞他的詞性是 Common words 或 rare words,我們稱為 common locally 及 rare globally
接著下來就是權衡兩者了
TF-IDF:Term frequency – inverse document frequency (tf-idf)
其就是作為 common locally 及 rare globally 的權衡的演算法
Term frequency 只考慮局部的狀況,只看某人正在看的文章,簡單的統計著單字出現的次數
接著我們要做的就是根據 inverse document frequency 來減少這個統計數字的權重,如下面的式子
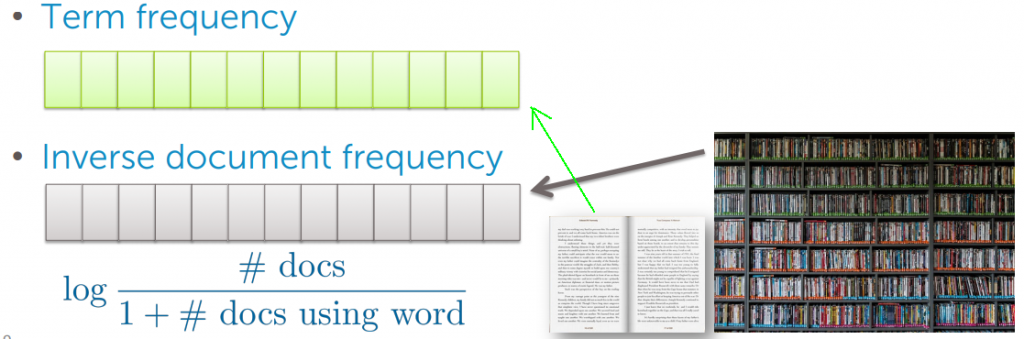
為什麼是這個式子呢
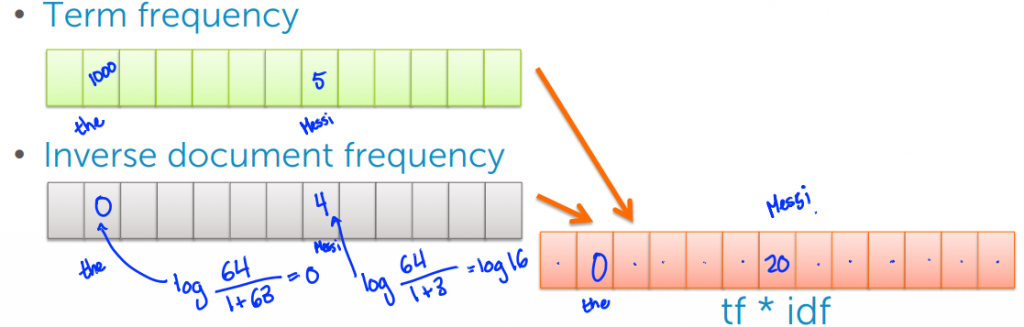
我們可以看兩個例子,分別是 the(出現1000次) 與 Messi(出現5次),詞料庫只有64份文件
在這個 case 當中 the 只在63個文件中出現,此時其權重就會為0
而 Messi 只出現在3個文件當中,此時權重就會為4
最後我們只需要將兩個向量相乘,來得到一個新的 Sparse matrix
我們已經討論了如何表示文件及衡量它的相似度,接著我們可以開始來關心如何檢索文件
假設某人正在閱讀一篇文章,假設他很喜歡某篇文章,我們希望推薦它文章給他
最熱門的方法是的方法為 nearest neighbor search
為了實現這個演算法,我們需要定義一個 distance metric 以此來衡量我們之前討論過得相似度
這個演算法的輸出是一個相關文章的集合
nearest neighbor search 的一個特例叫做 one nearest neighbor
當搜索查詢文件檔時,返回的只是一篇最相關的文章,這個演算法很簡單,我們只要搜尋詞料庫中的每篇文章
不斷的比較彼此的相似度,比較完全部的文件檔後,我們將可以返回最相關的文章給讀者
Search over each article in corpus
Compute s = similarity( Previous,now )
If s > Best_s, record = s and set Best_s = s
Return Best_s
這個演算法的一個變形叫 K-Nearest Neighbor
這個演算法將返回相關K個不同的文章集合給讀者,實現這個演算法除了保留當前最相關的文章,還需要一個優先陣列來存放目前找到k個最相關的文件檔



 iThome鐵人賽
iThome鐵人賽